I’m starting to read a book called Probabilistic Programming and Bayesian Methods for Hackers by Cameron Davidson-Pilon, who is the Data lead at Shopify. You can download it for free; each chapter is an IPython notebook. I’ve read the first four chapters so far and have really enjoyed them. This book is perfect for people like me who have a foundational understanding of Bayesian methods as well as comfort coding in Python (specifically, using the data stack). I like how he writes very concisely, and provides original examples.
In Chapter 1, the first example given is the famous “Given x tails and y tosses, is the coin fair or not”. I’m familiar with the frequentist approach, which is to model the coin flip as a random Binomial variable ~ B(y, 0.5) and determine the probability of getting a result as extreme as x. When y is large, the distribution converges to Normal. Here is the R code:
passum=0.5# by proportion
proptest=function(tailnum,tosses){phat=tailnum/tossesstdev=sqrt(passum*(1-passum)/tosses)zscore=(phat-passum)/stdevround(1-pnorm(zscore),4)}# by count
freqtest=function(tailnum,tosses){phat=tailnum/tossesstdev=sqrt((passum*(1-passum))*tosses)zscore=(tailnum-passum*tosses)/stdevround(1-pnorm(zscore),4)}# or simply
simpleway=function(tailnum,tosses){1-pbinom(tailnum,tosses,passum)}
So, for example, the chances of getting 550 or more tails in 1000 tosses with a fair coin is about 8 × 10-4. However, with smaller sample sizes (i.e., tosses), it is not always accurate to make the normality assumption.
This is when the Bayesian approach comes in handy. Like before, we can model the flips as a Binomial variable (or, multiple Bernoulli variables).The conjugate prior for the Binomial is the Beta distribution. Basically, what this means is that if the likelihood function is Binomial and the prior function is Beta, then the posterior will also be a Beta function.
The following is an example of how the curves shift as the sample size grows. I adapted this from the Python version in the PPBMH book.
set.seed(2015-09-04)n_trials=c(0,1,2,3,4,5,8,15,50,500)data=rbinom(tail(n_trials,1),1,0.5)# 0 tails, 1 heads
x=seq(0,1,length=100)plotme=function(N,dat=data){if(N==0){heads=0tails=0}else{heads=sum(dat[1:N])tails=N-heads}y=dbeta(x,1+heads,1+tails)plot(x,y,type="l",xlab=expression(paste(bolditalic(p),", probability of heads")),yaxt="n",ylab="",col="#E66700",lwd=4)if(N==0)rect(min(x),0,max(x),max(y),col="#FF9C4D",border=NA)elsepolygon(c(0,x,max(x)),c(0,y,min(y)),col="#FF9C4D",border=NA)abline(v=0.5,col="black",lty=2)legend("topright",legend=paste("observe",heads,"heads and",tails,"tails"),fill="#FF9C4D",cex=0.75)}invisible(lapply(n_trials,plotme))
As shown, the probability distribution goes from Uniform to one that resembles the standard Gaussian as more evidence is provided, since the evidence was taken from a distribution corresponding to a fair coin. So, if the coin were biased, then we expect the posterior distribution to look more skewed towards the true (biased) mean.
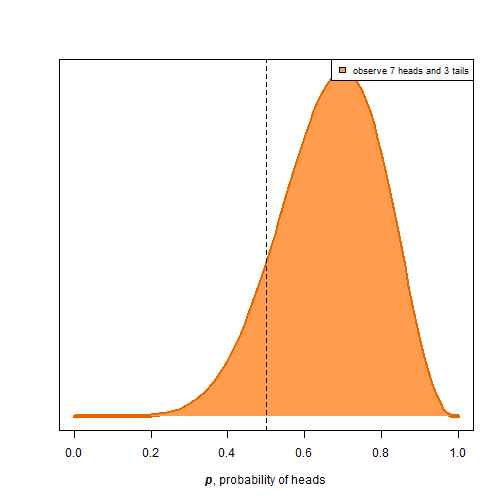
With small samples, the results might seem biased even if the coin is actually fair. In these situations, it’s much more intuitive to think of the real distribution transforming as more information is provided. For example, if we flip the coin 10 times and see 7 heads and 3 tails, here is what the distribution would look like:
data3=c(0,0,0,1,1,1,1,1,1,1)# order doesn't matter
plotme(10,data3)
Most of the area is in the 0.65-0.75 region rather than the 0.45-0.55, so given the result, this coin is more likely to be biased than fair. However, it’s probably more Bayesian to say that there is a 13.02% chance that a coin is fair given the observations. This is much more interpretable than conducting a hypothesis test and concluding that, “if the coin were fair, there is a z chance to observe a result as extreme”.
Back to reading! And again, you can (and absolutely should) download the book for free here. I can already tell it’s going to be a good one!
If you have any feedback or questions for me, please shoot me an email at melodyyin@u.northwestern.edu. Thank you!
Flowing Data, a blog I wish I had followed sooner, featured an interesting graphic a few days ago. It was a visualization of a woman’s dating history for the past 8 years. Intrigued, I went to her website and discovered that she graduated from Northwestern the same year as me! She also had plenty of other cool data/vis projects, like keeping a tally of how many times she and her boyfriend each apologized as well as noting what the reasons were for doing so. Her page introduced me to the idea of the “Quantified Self”, meaning that the individual tracks various aspects of his/her life in order to live better. I followed a couple of QS blogs on feedly (another site I wish I discovered earlier) and have really enjoyed what I read - I am excited to begin tracking my life’s data!
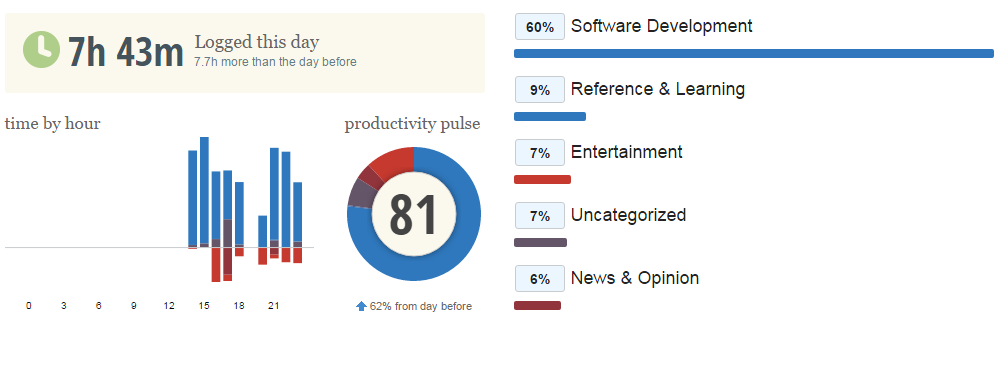
This morning, I downloaded RescueTime, an application that runs in the background and records the amount of time a user spends on websites and other apps. All activity is divided into categories, and what I really like is the categories are already well-defined without me having to sort them myself. For example, there is a category titled software development, and I have labeled it as a “productive” activity; contributing to this category is the amount of time I’ve spend on RStudio, StackOverflow, and in my text editor. Similarly, RescueTime knows that recode.net belongs in the “News & Opinion” category, and wikiwand in “Reference & Learning”. I’ve had it running for about 4 hours so far on my laptop, and I’ve spent about half of my time on software dev. Another cool feature is that it syncs every minute or two, and doesn’t seem to have any noticeble effect on my laptop’s performance! Here is a screencap of my dashboard at the end of the day:
They also have an API and it seems like I’ll be able to query the data and do some interesting analysis once I collect more data! I hope RescueTime will help keep me accountable for staying productive for the majority of the day and help me find patterns (if any; I like to think I am unpredictable) in browsing behavior and productivity.
Another (iOS) app I downloaded this week related to QS is called Pomodoro, in reference to the well-known Pomodoro Technique. It’s free and the user interface is clean and beautiful. Basically, the Pomodoro Technique calls or 25 minute work / 5 minute break cycles. I find that it really helps me to complete short tasks (you know, the ones that should’ve only take about an hour or so but somehow took up the entire afternoon). I don’t use the timer consistently for every task, so I’m not sure how much value there is in analyzing the results, but perhaps I’ll think of something later on. In any case, it has worked super well in boosting my productivity and I will likely continue using this method for a very long time!
Anyhoo, I just wanted to share my discoveries and also publicly announce my commitment to the QS lifestyle. Now who wants to buy me a FitBit…?
If you have any feedback or questions for me, please shoot me an email at melodyyin@u.northwestern.edu. Thank you!
Lyft seems like a great company to work for. I checked out their job listing section to see if there were any matches, but all available openings in the Analytics department as well as their Data Scientist role were for more experienced candidates. There was a SWE position for new grads, so I clicked out of curiosity. At the bottom of the page, was this:
Programming Challenge (Optional)
Calculate the detour distance between two different rides. Given four latitude / longitude pairs, where driver one is traveling from point A to point B and driver two is traveling from point C to point D, write a function (in your language of choice) to calculate the shorter of the detour distances the drivers would need to take to pick-up and drop-off the other driver.</br>
A pretty vague prompt, but it piqued my interest. I envisioned two cars driving in my mind, and immediately thought that this would be the perfect opportunity to use NetLogo.
Basic Model
The setup was straightforward: two origin points with a car at each of them and two destination points. The origins and destinations were patches (different colored and with their corresponding label), and the cars were turtles. Originally, I designated all of them as turtles, but I realized that would have been a poor design choice since only cars move. The locations were set using sliders. The agents could be easily instantiated using set <varname> self as they were being created. The shorter detour could simply be determined by asking for the distancexy from origin to destination for both drivers.
Extensions
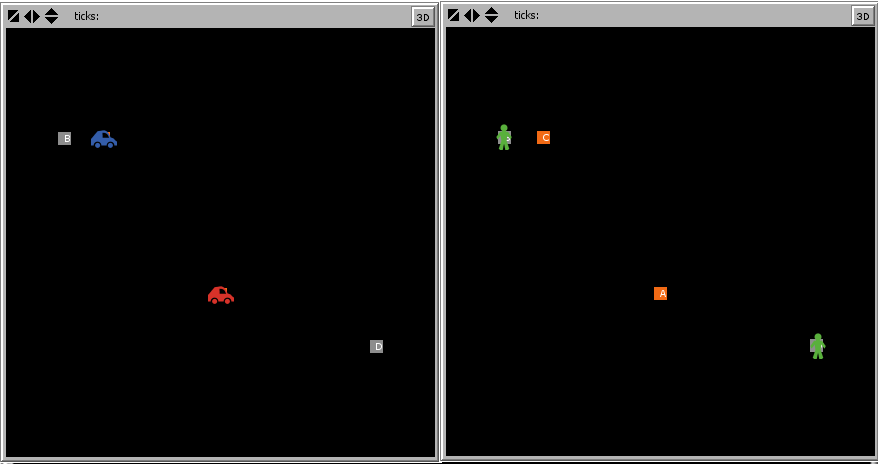
In my model, I made the driver not operating the vehicle into a person figure, and this rider “climbs in to the car” by staying invisible while traveling with the driver. The rider becomes visible again once he is dropped off. The driver also morphs into a person figure once he reaches his destination and both persons turn green to signal that the detour has been completed. Getting the direction of movement is as simple as calling face <target>. patch-here and turtles-here are useful for determining whether a location has been reached.
Here is what the start and end views look like:
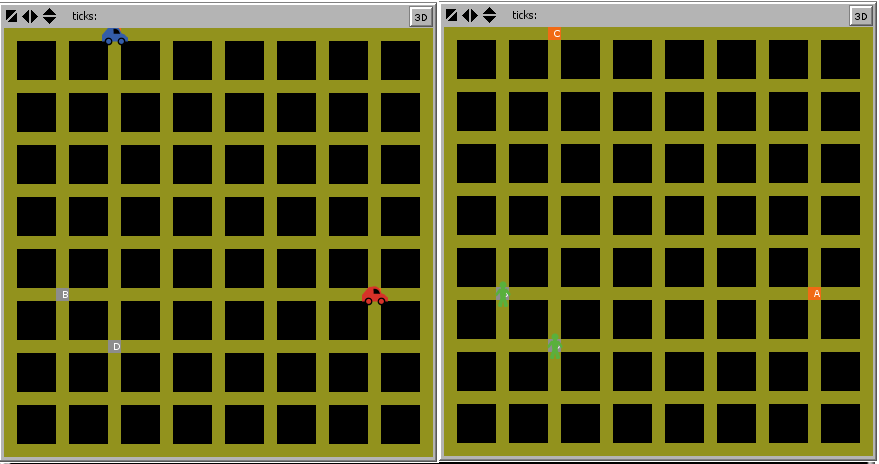
At this point, I had answered the prompt Lyft provided, but I wasn’t satisfied. It was wildly unrealistic that the cars could travel anywhere, so I decided to implement a grid system to mirror the view that users see when hailing a Lyft from their phones. Since the cars can only travel on the grid, the Euclidean distance measure had to be changed to Manhattan distance. Also, the direction that the car travels can only be 0 90 180 270 or 360. I enforced this rule by rounding up the desired direction (i.e., the direction of the next stop) to the nearest multiple of 90. To prevent the car from cutting across restricted areas, I reset the direction each time the patch ahead is not part of the grid.
Here is what the start and end views look like with the grid enabled:
The model can be found here. I have also uploaded a demo for this model.
Case for NetLogo
Even though the challenge could be solved using pretty much any language, NetLogo is the best fit since the traffic system builds upon the collective behaviors of drivers and their interactions with their environment. The built-in patch and turtle agents allow classes to be instantiated quickly and functions to be called easily. And of course, the visualization component is pretty superb for debugging and for a stronger understanding of the system behavior! I had a lot of fun building and extending upon the prompt given.
There are several additional extensions that can be applied to this model. All can be implemented within NetLogo.
Traffic signals and other cars on the road
One-ways and dead-ends
Driver gets picked up enroute (i.e., not at the start position)
Driver preferences (e.g., prefer to go straight rather than make turns, prefer highways over local roads, prefer furthest route once passenger is picked up but shortest when going to his/her own destination)
If you have any feedback or questions for me, please shoot me an email at melodyyin@u.northwestern.edu. Thank you!