31 Jul 2015
I’ve done 3 data challenges for Data Science/Analyst positions in the past few weeks. Below are a few things I’ve learned from experience; I hope they can be of help to others who are starting the data science interview process:
- Start early. Even if the main task/prompt doesn’t seem that challenging, reading in the file and cleaning up the data may take a long time, especially if the format is unfamiliar or the file size is large.
- Code matters… This may be kind of obvious, but you’re being judged on the quality of your code as well as the depth/originality of your analysis. This means - comments where necessary, watch the number of temp variables (piping ftw), wrap frequently used commands into functions, be aware of efficiency…etc. Even though the code that you write won’t be reused, it’s still important to write it as if it were going to be. Plus, clean code helps with debugging.
- …and so does the presentation. Again, might be obvious. I do data cleanup/processing in Python, and then analysis with R in RStudio (I had used RGUI for the longest time but finally made the switch to RStudio…it’s so much better). I use knitr to turn my R code into a report.
- Have a plan/timeline. For me, I sometimes get overexcited about certain packages or concepts that I encounter along the way, but really do not have much to do with the challenge itself, so I have to remind myself not to get sidetracked. Additionally, I sometimes focus so intensely on one part of the assignment, testing different ways I could have tackled the problem or making sure the presentation details are perfect, and that I spend way longer on it than I should, leaving little time for the questions at the end. You will generally be given about a week for the assignment, and although that seems like a lot, you still have to be disciplined and treat it like a timed assignment.
- Test functions. Unit tests are pretty important to writing quality, bug-free code. Developers know this, but I don’t think this is really stressed for data scientists. Doing so does take extra time, and your potential employer won’t see the effort you put into building your test suite, but it ensures the accuracy of your analysis. A naive analysis is better than getting the wrong results.
Overall, I think practicing and learning from mistakes is the best way to get better. I wasn’t able to clear those data challenge rounds, so I spent the last few weeks trying to improve. I recently redid one of the data challenges I sent in about a month ago and the differences in terms of accuracy, quality/efficiency, and readability between the one I submitted and the redo were startling.
If you have any feedback or questions for me, please shoot me an email at melodyyin@u.northwestern.edu. Thank you!
07 Jul 2015
This is the second part of my review on the patient tracking system project. You can read part one here.
At the end of my eight weeks working on the project, I spoke with the postdoc and professor about returning in the following academic quarter, and they agreed! So, after spring break, I resumed my position in the lab.
Due diligence
Much like working in a startup, working on a project solo has its perks as well as issues. In the first eight weeks, I enjoyed the flexibility and autonomy it allowed. However, after I returned to the project, I felt the weight of having to do everything myself when a lot of the less stimulating work needed to be done. An additional Kinect sensor was added, so now there were suddenly twice as many clips to label. Additionally, I encountered problems with VGB that wiped out hours of work; at one point, building the database failed repeatedly due to memory overflow. These problems were really frustrating because they were not at all difficult, but were extremely time-consuming to fix.
Around this time, the postdoc also suggested that I should be implementing robustness checks. As in, we knew that the angle and height of the sensor affected results somewhat, but we didn’t know how much. Without going into too much detail, I found that setting the Kinect at different configurations had a dramatic effect on accuracy rate. However, the database which contained all of the clips as well as the database with the testing clip’s configuration had similar performances.
MLE vs. MAP
The sample code had originally returned all of the activities with a confidence value greater than 0 for each frame. In other words, it was highly likely that each frame was labelled with multiple gestures and start/end times overlapped. This didn’t make sense for my purposes, since all of the gestures I was working with were distinct. So, I changed the code to reflect a maximum likelihood estimation (MLE) approach by finding the gesture with the greatest confidence level per frame and attaching the result to the frame if the confidence exceeded the threshold. Then, I started to think about how I could extend this further. I knew that although finding the optimal thresholds would increase the accuracy, they would need to be readjusted once new training clips were added. But, I realized that there were some gestures that could not be in sequence. For example, a person has to get into the bed before he/she moves around in the bed. Disallowing moving in bed to be triggered unless the previous gesture was itself, laying in bed or getting into bed seemed like a good idea until the professor advised that the Kinect may not be turned on all the time (e.g., the first gesture may actually be Moving in Bed). However, even though absolute restrictions could not be applied, I could still make probabilistic assumptions about the gesture sequence. That is, there are plenty of claims I could make for P(next gesture|current gesture).
This realization led to the creation of a transition matrix. At first, I tried assigning probabilities to each gesture so that P(ALL GESTURES|current gesture) would sum up to one. After I implemented this, I realized that now using one threshold for all gestures did not produce the expected results. Then, I tried penalizing only the gestures that were unlikely, and this approach seemed to work well. So, I set up three “bins”: one for likely gestures, one for probable and one for impossible. Those in the likely bin receive no penalty and are triggered when their confidence values exceed the threshold. Gestures in the probable category get a 50% penalty, so their confidence values have to be 2*threshold to be triggered. Lastly, the impossible gestures have to exhibit a confidence value of ~4*threshold to be triggered; the reason that they were not eliminated completely is due to the possibility that the previous gesture was mislabelled.
To summarize, here is an example of what the transition matrix looked like:
| |
G1 |
G2 |
G3 |
… |
| G1 |
1 |
0.5 |
0.23 |
… |
| G2 |
0.5 |
1 |
0.5 |
… |
| G3 |
0.23 |
1 |
1 |
… |
| … |
… |
… |
… |
… |
Depending on the previous and current gesture, the appropriate transition value was applied to the raw confidence value. Since there is no reason to expect one gesture over any other to be the first in the sequence, MLE is used when the previous gesture has not been defined. Unlike thresholds, the transition values remain the same even after new training clips are added.
Results
This approach gave pretty good results, and outperformed MLE because it dramatically reduced the number of false positives. Previously, there had been some noise in the detection results. For example, if a gesture lasted 50 frames, while the majority would be tagged as the correct gesture, a few of those were incorrect. A common pattern I observed before the transitions were implemented was Sit, Moving in Bed, Sit, Moving in Bed,…etc. Implementing transitions eliminated these types of errors.
However, when a frame was mislabeled, this affected all of the following classifications. The wrong gesture could block all of the (correct) labels that the detector tries to make, because they would be penalized by the transitions. To counter this effect, I allowed the gesture sequence to restart if no activity had been detected for a certain number of frames. This helped to restore the correct state after a mistake had been made. Here is an example of how this works:
- Before: G1, __ , __ , __ , __ , …
- Ground truth: G2, G3, G2, G3, G2, G3
- After: G1, __ , __ , ___ , G2, G3
Finally, the detector was evaluated on various testing clips. Solid results were achieved across the entire gesture database, and both the precision and recall for all gestures were much higher than they were when I turned in the project report last quarter. Notably, lifts, walking and bed movements had near-perfect performance. Sit and fall were satisfactory, with ~80% precision and ~70% recall. Getting into bed and out of bed did not perform as well. When I looked at the raw confidence levels for the sequence of frames where these two gestures were occurring, I saw that either the confidence was very low or the gestures were not triggered at all. This result suggests that these two gesture databases are insufficient, so it’s possible that the range of training examples was too limited.
Discussion
Although VGB is a great solution for those who want to use the Kinect for gesture recognition, a major disadvantage of the tool is that it doesn’t allow features to be extracted. VGB calculates 38 different features from the training clips, but the developer is not able to access these values or the coefficients for the predictors. It does show what the features are, and which ones are the top contributors to the final gesture classifier, but not much more detail is provided. Therefore, adding additional training clips or applying post hoc methods is really the only way to get better results. I would have liked to compare performances of various learning algorithms against AdaBoost, VGB’s default, if not for any accuracy gains then for my own learning purposes. The postdoc and I did spend a few hours going through the AdaBoost algorithm to make sure we fully understood (or at least, had a good guess for) what was going on behind the scenes, but having some official documentation would have been appreciated.
Looking back on the project from the finish line, I feel a lot of gratitute towards the professor and postdoc who worked with me, and I also feel proud of the work I have done. I do wish I could have spent more time developing the interface in the second round, but improving the accuracy was more important. This project was truly one of the highlights of the past year I spent as a graduate student, and I am excited about the possibility of making more contributions in the healthcare field in the not-too-distant future!
If you have any feedback or questions for me, please shoot me an email at melodyyin@u.northwestern.edu. Thank you!
03 Jul 2015
Yesterday, I turned in the report which marked the end of an independent study project I have been working on since the beginning of the year. I was fortunate to have the opportunity to be working on such an exciting project without much knowledge of machine learning or computer vision. This was also my first purely technical project, so I am grateful that the professor heading the lab gave me a lot of trust and space for creativity.
The code that I wrote will not be on GitHub, but I will go into detail about some of the methods and implementations that I have used, which will hopefully be as illuminating as viewing the actual code. Below I will review the milestones I have achieved during the first half of the project, as well as some lessons learned (both technical and uh, life-related). There will be a follow-up post in the next few days on the second half.
Setup
The goal was to build an activities detector that would be able to recognize movements of a hospital patient - 11 common gestures were identified; they were: arm and leg lifts (5), bed-related movements (3), walking (1), sitting (1) and falling down (1). The Microsoft Kinect camera would be placed in the hospital room to track the patient.
The previous developer who worked on this project had utilized a few of the Kinect APIs to extract skeletal/joint information and then wrote code that defined what each gesture should look like. It went something like, if the arm joints were moved x number of degrees, and x was greater than some minimum value y then it was concluded that an arm lift has occurred. More generally, it involved hardcoded values based on (reasonable) assumptions about each gesture.
Visual Gesture Builder (VGB)
When I joined the project, a new release of Kinect SDK had just been pushed. One of the tools it contained was called Visual Gesture Builder, which allows the user to generate gesture databases using recorded training clips. The main benefit VGB offered was a machine learning approach to gesture detection, rather than relying on heuristics. So, instead of writing hundreds of lines of code defining one gesture, I could record just a few clips and achieve similar performance (VGB uses AdaBoost on 38 features for classification, so writing the code to generate these features alone would have taken several days). Additionally, it allowed the user to easily enrich the gesture profile. For example, activities look different depending on the height and angle of the camera, so I could just teach the detector through addition of new training clips. All in all, VGB was a perfect solution for me, especially considering that I was a team of one, working on the project part-time, and I did not have much experience with programming in C#.
Then, I started to gather training clips from other students. A cool feature of VGB is that everything not tagged as a positive example is classified as a negative example, so I was able to achieve decent accuracy fairly quickly. VGB also offers a “Live Preview” feature that allows the developer to see all the gesture databases within a VGB solution and their results. In other words, I was able to see which activities were triggered and make adjustments using the VGB interface.
If you want to learn more about VGB, two Microsoft engineers gave a great tutorial here.
Writing code and creating the interface
Once the complete database was trained and ready to go, it was time to start coding. Microsoft provides plenty of sample codes to get developers going. The starter code I used was called DiscreteGestureBasics and to get it to perform the most basic function (i.e., display something when one of my gestures was detected), all I had to do was define my 11 gestures and iterate through the database I built with VGB.
At this point, I had a nifty interface with six boxes, one for each body that the Kinect is able to track, and the appropriate box lit up when one of the gestures from my database was detected. However, a hospital staff member should be able to glance at the interface and instantly get the information he/she needed. So, the name of the gesture, lift count, and angle were added, and when nothing was happening, the previous gesture (now inactive) was displayed (this was needed because otherwise each result would be displayed only for a few miliseconds). Also, the detection results needed to be sent to the database, so each activity needed to have a beginning/end time stamp.
A postdoc also working in the lab began to work on the angle detection while I started on the counts. This seemed simple enough to implement, but all I was receiving from VGB API was the confidence levels per gesture per frame. There were ~30 frames per second, and a single lift takes a minimum of about a second, so clearly I could not just increase the count for every active frame; the counts needed to be derived from the confidences.
Thanks to VGB’s “Live Preview” function, I was pretty familiar with the shape of the confidence intervals, and noticed two types of intervals among the 11 gestures in my database. Lifts had a distinct rises and falls similar to this:
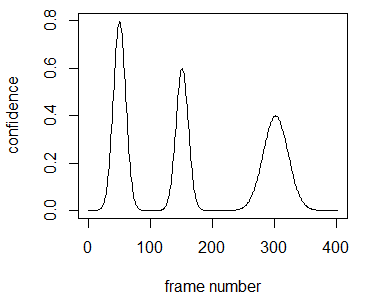 while the others looked like this:
while the others looked like this:
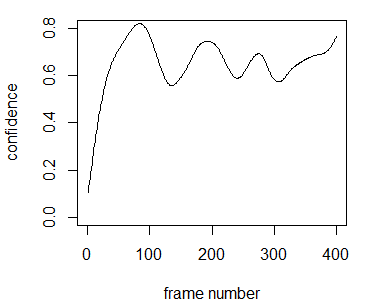 I then set a threshold (i.e., any detected result with a confidence value
I then set a threshold (i.e., any detected result with a confidence value < threshold is considered noise) and kept track of when the threshold was broken. For the lifts, I simply added to a counter when the threshold was broken and initated the start time here; similarly, the end time was the time of the last frame which exceeded the threshold. For the other gestures, a count was not needed and it also did not make sense to add “Walk” to the database each time the patient took a step or walked a bit, stopped, then walked some more (there would be several Walks consecutively, which is redundant). So, the start time is the time stamp of the first frame that breaks the threshold for a certain gesture given that the previous gesture is not the same as the current one, while end time is the time of the last frame which exceeded the threshold before the next gesture. The end time is also calculated when the sensor loses the body frame.
This setup worked great except for the “Moving in Bed” activity. It fell into the second category of gestures, so the start and end time covered the patient’s entire time in bed, even when he/she was laying still. So, a fourth gesture in the bed movements category was introduced as a helper gesture to Moving in Bed - Laying in Bed. This allowed more accurate portrayal of events.
My eight weeks of work pretty much ended here. I had built a database that recognized a dozen gestures and an interface which showed provided readable information on detected results. I had not done any formal analysis on accuracy at this point, but I did not feel confident about the performance of most of the gestures (lifts performed well because they are easy to train and distinctive). It was clear that my next major task would be to focus on increasing the accuracy.
Discussion
I haven’t played any games on the Kinect, but I do own a Wii. People who have had experience playing either know that it is very easy to “trick” the sensor. There are also times when the sensor fails to detect that you have made the right moves. For example, a flick of the wrist in Wii Tennis has the same effect as a full swing of the arm. This problem occurs often with the Kinect. From the view box, the body frame is only fully intact when the person is centered, standing upright and still; the amount that it deviates from this position is reflected in the body representation. I believe that this is the main reason that gestures like falling and sitting down are harder to train than walking or lifts: the sensor isn’t able to represent these gestures so any data coming in or out will be misfigured (and to exacerbate the problem, falling and sitting down look very similar even with perfect representation).
Although I was the only person working on my project, there were a few other students who were also working on other related applications. I was excited to learn that many of the others’ projects built upon my results. For example, there was a group who built an iPhone app that contacted the hospital staff if a patient fell, and another created a website which showed video segments of patients performing certain activities. I didn’t have a partner, but there was a postdoc who acted as the project manager to the group of us. Through working with her, I realized that having teammates (even if they are not working on the same project as you are) is extremely important. Many times an idea crystallized because I was able to talk it through with her; also, explaining to another human your approach can often reveal holes in your logic or assumptions. And perhaps most importantly, it made the entire process more fun.
I spent about half of the eight weeks collecting training data and configuring VGB, and to be honest, I intentionally pushed off actually writing code because I was scared that I wouldn’t be able to do it. Everyone else on the team seemed like seasoned programmers, and the sample code looked pretty intimidating initially. Once I dove in, everything quickly started to come together, but making the jump took a lot of courage. Thus, above all, the most valuable lesson I learned in these eight weeks was that even when the task is challenging, the less time I waste doubting myself, the more time there is to improve.
If you have any feedback or questions for me, please shoot me an email at melodyyin@u.northwestern.edu. Thank you!
Continue to part 2