Patient Activity Detection Using Kinect for Windows v2 (part 1)
03 Jul 2015Yesterday, I turned in the report which marked the end of an independent study project I have been working on since the beginning of the year. I was fortunate to have the opportunity to be working on such an exciting project without much knowledge of machine learning or computer vision. This was also my first purely technical project, so I am grateful that the professor heading the lab gave me a lot of trust and space for creativity.
The code that I wrote will not be on GitHub, but I will go into detail about some of the methods and implementations that I have used, which will hopefully be as illuminating as viewing the actual code. Below I will review the milestones I have achieved during the first half of the project, as well as some lessons learned (both technical and uh, life-related). There will be a follow-up post in the next few days on the second half.
Setup
The goal was to build an activities detector that would be able to recognize movements of a hospital patient - 11 common gestures were identified; they were: arm and leg lifts (5), bed-related movements (3), walking (1), sitting (1) and falling down (1). The Microsoft Kinect camera would be placed in the hospital room to track the patient.
The previous developer who worked on this project had utilized a few of the Kinect APIs to extract skeletal/joint information and then wrote code that defined what each gesture should look like. It went something like, if the arm joints were moved x number of degrees, and x was greater than some minimum value y then it was concluded that an arm lift has occurred. More generally, it involved hardcoded values based on (reasonable) assumptions about each gesture.
Visual Gesture Builder (VGB)
When I joined the project, a new release of Kinect SDK had just been pushed. One of the tools it contained was called Visual Gesture Builder, which allows the user to generate gesture databases using recorded training clips. The main benefit VGB offered was a machine learning approach to gesture detection, rather than relying on heuristics. So, instead of writing hundreds of lines of code defining one gesture, I could record just a few clips and achieve similar performance (VGB uses AdaBoost on 38 features for classification, so writing the code to generate these features alone would have taken several days). Additionally, it allowed the user to easily enrich the gesture profile. For example, activities look different depending on the height and angle of the camera, so I could just teach the detector through addition of new training clips. All in all, VGB was a perfect solution for me, especially considering that I was a team of one, working on the project part-time, and I did not have much experience with programming in C#.
Then, I started to gather training clips from other students. A cool feature of VGB is that everything not tagged as a positive example is classified as a negative example, so I was able to achieve decent accuracy fairly quickly. VGB also offers a “Live Preview” feature that allows the developer to see all the gesture databases within a VGB solution and their results. In other words, I was able to see which activities were triggered and make adjustments using the VGB interface.
If you want to learn more about VGB, two Microsoft engineers gave a great tutorial here.
Writing code and creating the interface
Once the complete database was trained and ready to go, it was time to start coding. Microsoft provides plenty of sample codes to get developers going. The starter code I used was called DiscreteGestureBasics and to get it to perform the most basic function (i.e., display something when one of my gestures was detected), all I had to do was define my 11 gestures and iterate through the database I built with VGB.
At this point, I had a nifty interface with six boxes, one for each body that the Kinect is able to track, and the appropriate box lit up when one of the gestures from my database was detected. However, a hospital staff member should be able to glance at the interface and instantly get the information he/she needed. So, the name of the gesture, lift count, and angle were added, and when nothing was happening, the previous gesture (now inactive) was displayed (this was needed because otherwise each result would be displayed only for a few miliseconds). Also, the detection results needed to be sent to the database, so each activity needed to have a beginning/end time stamp.
A postdoc also working in the lab began to work on the angle detection while I started on the counts. This seemed simple enough to implement, but all I was receiving from VGB API was the confidence levels per gesture per frame. There were ~30 frames per second, and a single lift takes a minimum of about a second, so clearly I could not just increase the count for every active frame; the counts needed to be derived from the confidences.
Thanks to VGB’s “Live Preview” function, I was pretty familiar with the shape of the confidence intervals, and noticed two types of intervals among the 11 gestures in my database. Lifts had a distinct rises and falls similar to this:
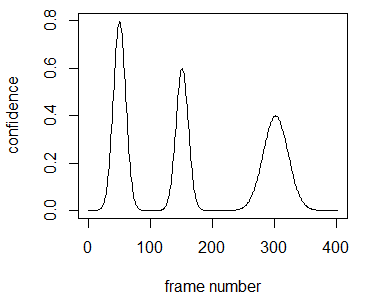 while the others looked like this:
while the others looked like this:
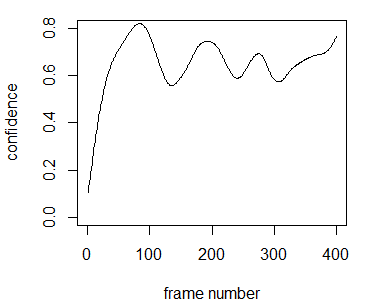 I then set a threshold (i.e., any detected result with a confidence value
I then set a threshold (i.e., any detected result with a confidence value < threshold is considered noise) and kept track of when the threshold was broken. For the lifts, I simply added to a counter when the threshold was broken and initated the start time here; similarly, the end time was the time of the last frame which exceeded the threshold. For the other gestures, a count was not needed and it also did not make sense to add “Walk” to the database each time the patient took a step or walked a bit, stopped, then walked some more (there would be several Walks consecutively, which is redundant). So, the start time is the time stamp of the first frame that breaks the threshold for a certain gesture given that the previous gesture is not the same as the current one, while end time is the time of the last frame which exceeded the threshold before the next gesture. The end time is also calculated when the sensor loses the body frame.
This setup worked great except for the “Moving in Bed” activity. It fell into the second category of gestures, so the start and end time covered the patient’s entire time in bed, even when he/she was laying still. So, a fourth gesture in the bed movements category was introduced as a helper gesture to Moving in Bed - Laying in Bed. This allowed more accurate portrayal of events.
My eight weeks of work pretty much ended here. I had built a database that recognized a dozen gestures and an interface which showed provided readable information on detected results. I had not done any formal analysis on accuracy at this point, but I did not feel confident about the performance of most of the gestures (lifts performed well because they are easy to train and distinctive). It was clear that my next major task would be to focus on increasing the accuracy.
Discussion
I haven’t played any games on the Kinect, but I do own a Wii. People who have had experience playing either know that it is very easy to “trick” the sensor. There are also times when the sensor fails to detect that you have made the right moves. For example, a flick of the wrist in Wii Tennis has the same effect as a full swing of the arm. This problem occurs often with the Kinect. From the view box, the body frame is only fully intact when the person is centered, standing upright and still; the amount that it deviates from this position is reflected in the body representation. I believe that this is the main reason that gestures like falling and sitting down are harder to train than walking or lifts: the sensor isn’t able to represent these gestures so any data coming in or out will be misfigured (and to exacerbate the problem, falling and sitting down look very similar even with perfect representation).
Although I was the only person working on my project, there were a few other students who were also working on other related applications. I was excited to learn that many of the others’ projects built upon my results. For example, there was a group who built an iPhone app that contacted the hospital staff if a patient fell, and another created a website which showed video segments of patients performing certain activities. I didn’t have a partner, but there was a postdoc who acted as the project manager to the group of us. Through working with her, I realized that having teammates (even if they are not working on the same project as you are) is extremely important. Many times an idea crystallized because I was able to talk it through with her; also, explaining to another human your approach can often reveal holes in your logic or assumptions. And perhaps most importantly, it made the entire process more fun.
I spent about half of the eight weeks collecting training data and configuring VGB, and to be honest, I intentionally pushed off actually writing code because I was scared that I wouldn’t be able to do it. Everyone else on the team seemed like seasoned programmers, and the sample code looked pretty intimidating initially. Once I dove in, everything quickly started to come together, but making the jump took a lot of courage. Thus, above all, the most valuable lesson I learned in these eight weeks was that even when the task is challenging, the less time I waste doubting myself, the more time there is to improve.